17 May 2018 - Matthieu Napoli
Serverless basically means "Running apps without worrying about servers". Obviously there are still servers involved, the main difference is that you do not maintain the servers and reserve their capacity. They are scaled up or down automatically and you pay only for what you use.
This article intends to explain what serverless means for web applications and more specifically for PHP.
Update: Since November 2018 AWS Lambda supports PHP via custom runtimes. Bref now takes advantage of that, you can read more about it at bref.sh.
What is serverless?
Serverless file storage
AWS S3 and other file/object storage are good examples of serverless infrastructure.
If you were to store files in your application (for example file uploads, images, etc.), the traditional solution would be to store them on a drive mounted in the server. The downsides would be that you would have to monitor it and scale up the volume in case it gets full. You would also pay for the whole storage space even if you used 10% of it.
The serverless approach is rather a virtual storage with no maximum capacity and managed for you. You would also pay only for the disk space you are actually using. That is what AWS S3 offers for example.
Serverless databases
The traditional approach to using a database in an application is to run MySQL/PostgreSQL/etc. on a server. You would have to maintain it (monitoring, backups, replication…) and the database would be limited to the resources available on the server (CPU, RAM, storage…). If you hit those limits you would have to scale the server up, which means effort and downtime. In the opposite case if the application barely uses the database you would still pay for the whole server.
The serverless approach is again to abstract the server away and hide how the database service is running. You would use the database just as before, however the resources dedicated to your database would scale up or down dynamically with the load. Monitoring, backups and replication would be handled for you. You would pay only for the resources (CPU/RAM/storage) the database actually uses.
While using serverless file storage is becoming more common, serverless databases are still a bit new. This is probably because databases are a lot trickier to manage than files. Good examples of serverless databases would be AWS DynamoDB (which is a NoSQL database) and "AWS Aurora serverless" which replicates MySQL or PostgreSQL. Note however that for now AWS Aurora serverless is still in private beta.
The same could be said about other kind of databases like message queues, caches, etc.
Serverless applications, aka FaaS
The "serverless" approach for applications is a bit trickier to imagine.
The "traditional" approach to running an application means executing the application on a server. That application would be a process running on a CPU and some RAM. The application would either act immediately (like an application executed on the command line, a CRON task…) or listen and react to external events (an incoming HTTP request, a TCP connection, a new message in a message queue…), aka a daemon.
For example the code for a HTTP API in NodeJS would contain:
-
the main script, starting a HTTP server on port 80, and a router handling requests, often through a framework like Express
The serverless approach takes things differently: instead of thinking about applications and processes, the application is considered as a collection of functions, also known as lambdas.
FaaS, which means Function as a Service, means that you only care about writing the function and that the FaaS provider will take care of running them.
Lambdas are invoked by events that can be:
- a HTTP request
- a new message in a message queue
- a new file in a file storage (like an AWS S3 bucket)
- a specific time to replicate the behavior of a cron (e.g. every day at 2am)
- etc.
If we take the same example as before, the serverless equivalent would be a NodeJS project containing 2 functions:
- a function that is set up to be called when a HTTP request calls GET
/users
- a function that is set up to be called when a HTTP request calls POST
/users
The serverless tooling takes care of the daemon part (e.g. the HTTP server and routing) and developers now have just to write multiple functions.
On AWS the HTTP server + routing is taken care of by API Gateway (you would basically define routes there), and the execution of the functions is done by AWS Lambda (a bit like Docker containers).
On a side note you do not necessarily have to split your application into many lambdas (one for each controller). You could also have 1 lambda that do the routing like before.
I do not know yet if one way is fundamentally better than the other, but this is definitely easier to get started with 1 lambda. This approach is also closer to current architectures and frameworks, especially in PHP where we migrated from multiple *.php files into a single index.php entrypoint a long time ago. I am not convinced that splitting everything again makes sense. I guess time will tell.
Advantages
Just like file storage and database, the main advantages are costs, scalability and the reduced amount of server maintenance.
Lambdas are executed on demand whenever they are triggered by an event (like an HTTP request). That means that if your application has no activity, nothing is running and the costs are close to 0. When your application receives a lot of requests, the FaaS provider runs as many instances as necessary to handle them. If there were to be 1000 HTTP requests at the same time, your lambda would execute 1000 times in parallel. This is useful for HTTP applications but also workers: you don't have to run a fixed number of workers at all time. Of course you could be limited by other non-scalable components of your architecture, like the database, if those are not "serverless" and scalable on-demand too.
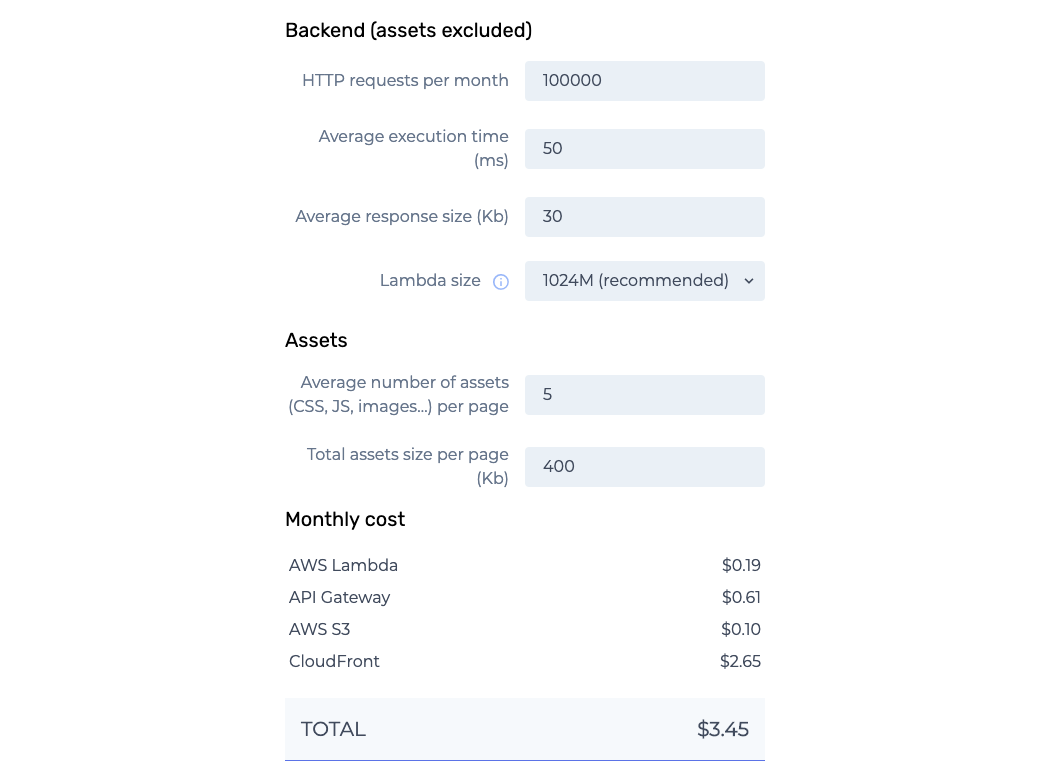
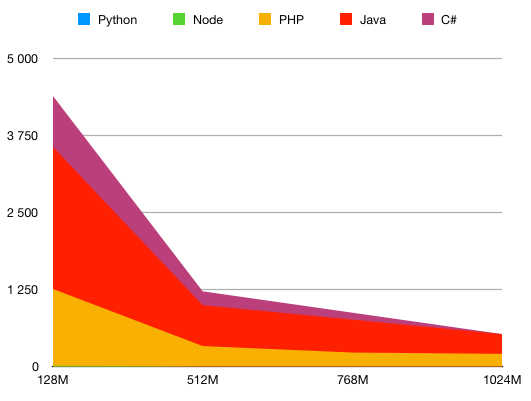
You usually pay by the time of execution of your lambdas. Try the AWS Lambda pricing calculator to get an idea. For HTTP applications however you will also pay for API Gateway and data transfer, and those can cost more than AWS Lambda.
Drawbacks
First the technology is new, compared to traditional solutions the tooling is basic and not mature. There is less expertise and less resources out there to get started easily and build something correctly. And since we lack perspective on the subject it is harder to distinguish the use cases where serverless makes perfect sense VS the cases were serverless is not useful.
Costs can be a drawback too: if you compare the cost of a high traffic application hosted on lambdas vs a lower level solution like bare-metal or VPS hosting, it's possible that serverless will be more expensive. This is because you pay for the CPU/RAM resources and the service of managing the infrastructure. If you have an infrastructure that is already working fine as it is, the switch to serverless may not be worth it.
A drawback usually brought up is vendor lock-in. While it is a legitimate concern, it is more and more mitigated as there are open solutions that provide alternatives to AWS and Azure (e.g. serverless on Kubernetes on your own machines). There are more and more tools abstracting the provider, allowing (theoretically) to switch from one provider to another more easily. I think that given enough time there will be as much vendor lock-in as there is with any hosting provider out there, i.e. not zero but acceptable (after all, switching hosting provider is always a cost, even with tools like Ansible, Docker, etc.).
Finally, a big drawback is that the serverless approach also impacts our code and our frameworks. Those are often not ready to work out of the box with lambdas because they were not imagined for those environments and architectures. While there is often not a huge effort required, it still is an effort (PHP is a good example for that and that is detailed below).
Serverless and PHP
Update: Since November 2018 AWS Lambda supports PHP via custom runtimes. The new version of Bref takes advantage of that, you can read more about it at bref.sh.
What is described below is now obsolete.
PHP applications are different than NodeJS/Java/Go web applications because they rely on Apache/Nginx + PHP-FPM for the HTTP server layer. In the NodeJS example, the application would start and listen on a port for HTTP requests, the same process would handle all the HTTP requests.
With PHP, each HTTP request gets its own process. When the HTTP response is emitted, the PHP application terminates and everything is cleared so that on each new HTTP request the PHP application starts from scratch again (this is a simplification). This behavior is in the end very similar to lambdas: for each HTTP request a lambda is booted, handles the request and dies (this is also a simplification). That is why I think lambdas make sense for PHP: the architectural gap is not huge.
Making PHP work on AWS Lambda
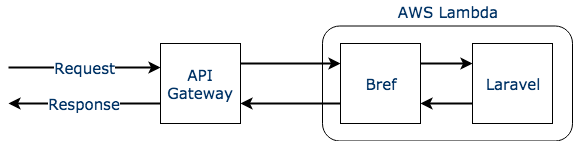
I will take the example of AWS Lambda because it is the most popular provider for serverless applications. Unfortunately AWS Lambda does not support PHP (supported languages are for example Javascript, Go, Python…). To run PHP we must add the PHP binary in the lambda and have, for example, Javascript execute it.
To sum up, what we will have to do:
- compile PHP for the OS used on lambdas
- add the compiled PHP binary to the lambda
- write a Javascript handler (the code executed by the lambda) that executes the PHP binary
- write a PHP handler (the code that will be executed by the Javascript handler)
- deploy the lambda
The content of the lambda would look like this:
bin/
php # our compiled PHP binary
handler.js # executes `bin/php handler.php`
handler.php # the PHP code we want to run on the lambdaNow that we have something working, let's add the missing parts: the input and output. Lambdas take event data as input, and return a response. The event data can contain data passed by the caller, or if we are in the context of a HTTP request the event will contain the HTTP headers, request, URI, etc. The response can contain anything we want to return to the caller, and for a HTTP context it should contain the HTTP response.
Since handler.js receives the event data directly, we can pass it to handler.php through several ways: using a specific temporary file for example, or more simply through a command parameter. That means running bin/php handler.php <the-event-data>. The event data would be encoded as JSON, read by the PHP script using the $argv variable and decoded using json_decode().
For the response, handler.php could write the response in a temporary file or event output it on stdout, then handler.js would read it and return it as the response of the lambda.
Here is an example of a handler.js if you are curious.
Introducing Bref
Needless to say that the above solution is not ideal because:
- you have to compile PHP manually
- you have to write and maintain a
handler.js for your PHP app
- you have to know the format of AWS lambda's event and response (for example for HTTP requests and responses)
- you cannot connect lambda's events and responses to PHP frameworks input/output or HTTP requests/responses
- you need to setup a deployment process from scratch to compile PHP, setup the project for the readonly filesystem (e.g. Composer install, prepare the caches…)
At first I tried to write a plugin for the serverless framework to support PHP but that didn't work out because of some limitations, and because that project is mostly about deployments.
I believe there are 2 problems to solve for the "serverless PHP" equation:
- deploy easily on serverless providers
- make PHP frameworks work just like before
I decided to write Bref to solve those problems.
The name bref means brief in french, in reference to the ephemeral life of lambdas. French speakers will also enjoy the double meaning of "Bref, j'ai déployé une application serverless" ;)
The deployment is implemented by a CLI tool, bref deploy, that wraps the serverless framework to add what is needed for PHP. On deployment, Bref will automatically install Composer dependencies (excluding dev dependencies) and optimize the autoloader for production. It is also possible to add additional tasks like building a cache before deployment (which is required by some frameworks like Symfony).
A simple PHP lambda can be implemented like this:
<?php
require __DIR__.'/vendor/autoload.php';
$app = new \Bref\Application;
$app->simpleHandler(function (array $event) {
return [
'hello' => $event['name'] ?? 'world',
];
});
$app->run();While that works, that does not solve the second problem because that does not work with PHP frameworks. I decided to tackle 2 ways of integrating with PHP frameworks:
- HTTP applications
- CLI applications
HTTP applications
PHP frameworks usually read the request from global variables, and echo the HTTP response to PHP's output and headers to global functions. That does not work on lambdas.
Fortunately modern frameworks abstract the HTTP request and responses with objects. What's even better is that we have PSRs for that (PSR-7 and PSR-15).
What Bref does is turn the lambda's event data (that contains HTTP request data) into a PSR-7 request object. We now have a HTTP request that frameworks can process. We call the framework with that request and get the PSR-7 response in return. We turn that response object into a valid AWS lambda response and return that to handler.js.
By abstracting that with PSR-15's RequestHandlerInterface (and adapters for frameworks that are not directly compatible) we can support most frameworks with very little effort for the end user.
Here is an example with the Slim micro-framework:
$slim = new Slim\App;
$slim->get('/dev', function ($request, $response) {
$response->getBody()->write('Hello world!');
return $response;
});
// Instead of calling `$slim->run()` we use Bref
$bref = new Bref\Application;
$bref->httpHandler(new Bref\Bridge\Slim\SlimAdapter($slim));
$bref->run();In short we use PHP frameworks just like usual but instead of running the framework directly we pass it to $bref->httpHandler(...) (for those curious here is what happens with the handler when $bref->run() is called).
CLI applications
Many frameworks let us create CLI applications (Symfony Console, Laravel Artisan, Silly…). Just like with HTTP, those frameworks read from global variables and output to stdout which doesn't work on lambdas.
But again like with HTTP, frameworks have built object-oriented abstraction over the CLI input and output.
Bref adds support to executing CLI commands in production using the bref cli command:
- run
bref cli -- [arguments and options] on your machine (everything after the -- is considered as arguments and options to the target CLI command)
- the
bref CLI tool will invoke the lambda and encode the provided arguments and options in the event data
- the lambda will recognize that it is called as a CLI and will decode the arguments/options from the event array into
Input and Output objects
- Bref will run the CLI framework (Symfony Console, etc.) with those objects
- it will encode the output into the lambda's response
- the
bref CLI tool receives the response and displays the output
Here is an example with a Silly application (which is a wrapper around the Symfony Console):
$silly = new \Silly\Application;
$silly->command('hello [name]', function (string $name = 'World!', $output) {
$output->writeln('Hello ' . $name);
});
$app = new \Bref\Application;
$app->cliHandler($silly);
$app->run();Running the command looks like this:
$ bref cli -- hello Bob
Hello Bob
# running the same command locally:
$ bin/console hello Bob
Hello Bob
State of the project
I want to emphasize that Bref is currently a beta project. As explained above serverless architectures is still new and many choices in Bref are not definitive. My goal in sharing this project is helping others try out serverless, and to help moving forward.
Just like with any buzzword there is hype, and there is distrust because of the hype. Bref is meant to help you make your own mind, not sell you a silver bullet.
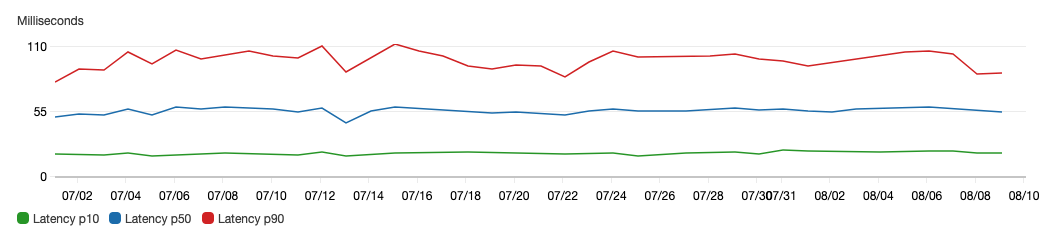
The project is new, there are many limitations and drawbacks and there is still a lot to improve. I take the habit of filling the code with very detailed TODOs, contributors are welcome. Regarding performances (because I know that's in everyone's mind) there is obviously a penalty to executing PHP CLI like this on every request. Some benchmarks estimate it at 20ms per request, which is acceptable in many scenarios. I also think there is a lot of room for improvements, for example regarding opcache. I don't want to get too hung up on that.
I am using the project in production on a few small scale projects and it does the job. Like semver allows, I am keeping BC only between patch versions while in a 0.*.* numbering. In Composer you should use ~0.x.0 instead of ^0.x.0 to avoid BC breaks until a 1.0.0 version.
Case studies
As explained above most of this is quite new, I am collecting case studies to show what we can expect from serverless PHP applications.
-
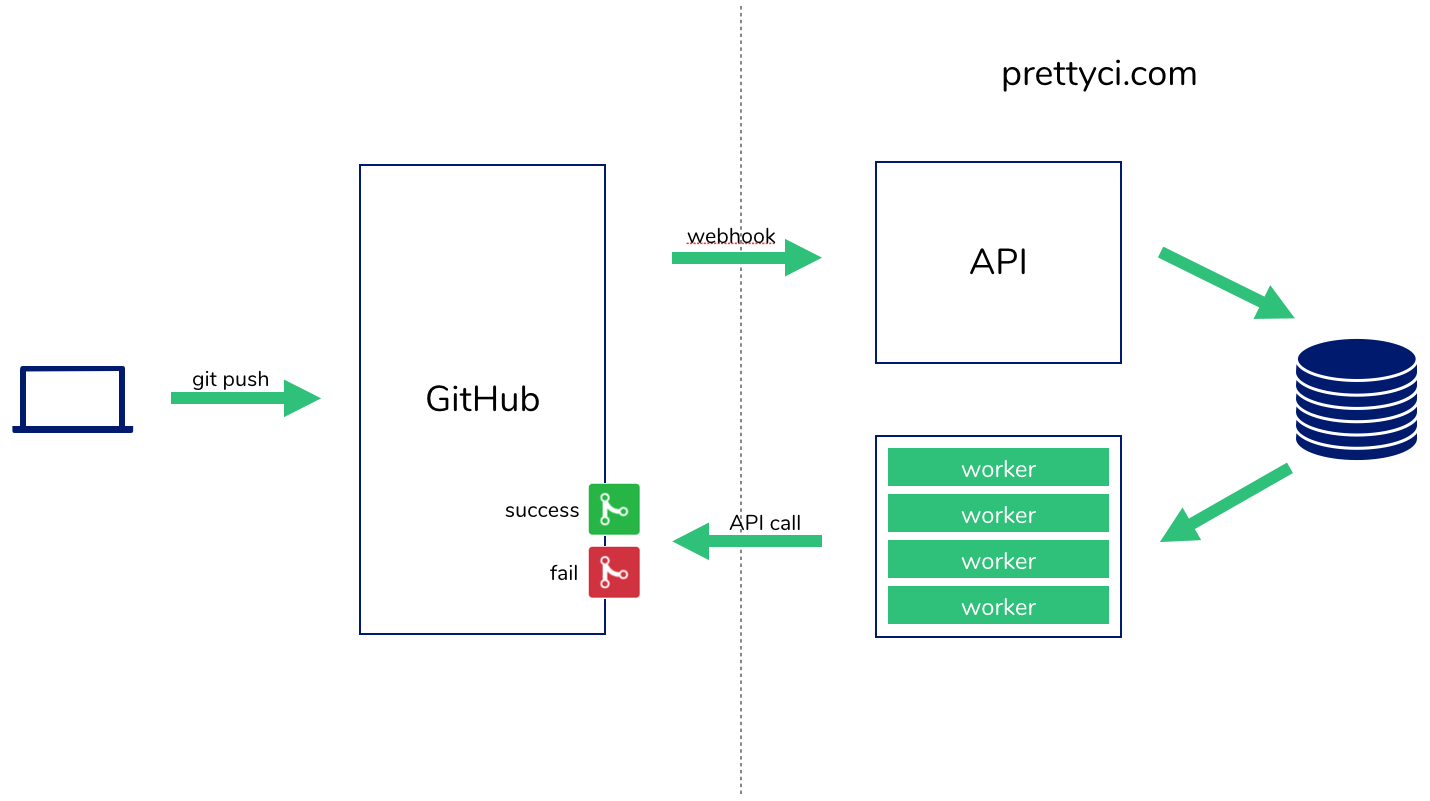
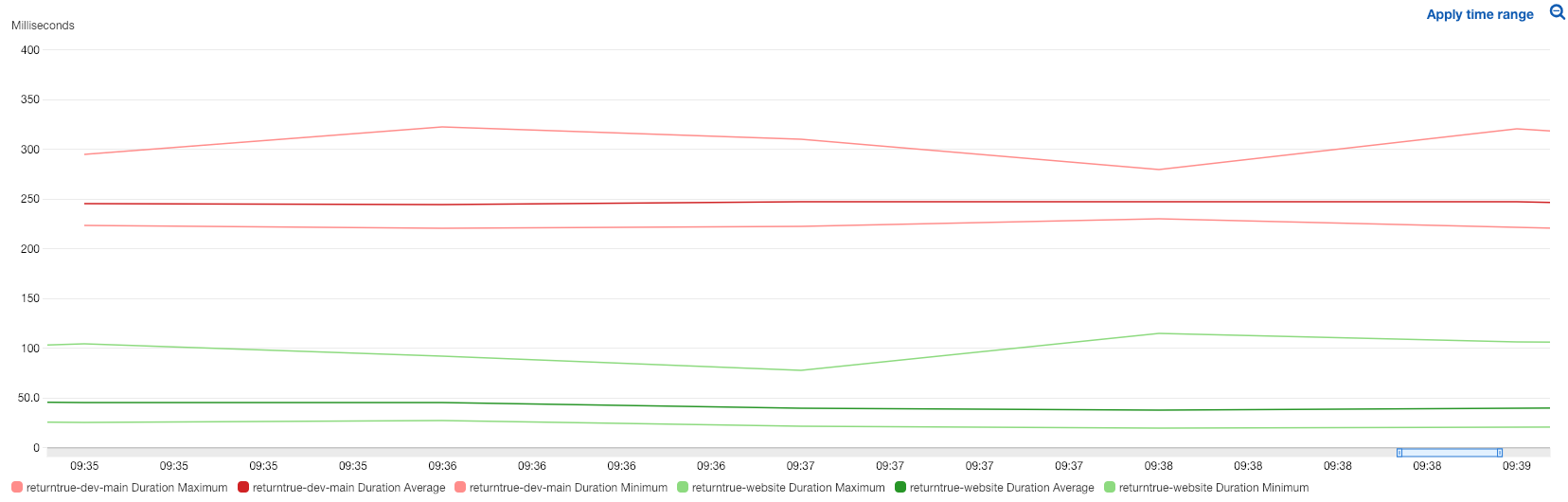
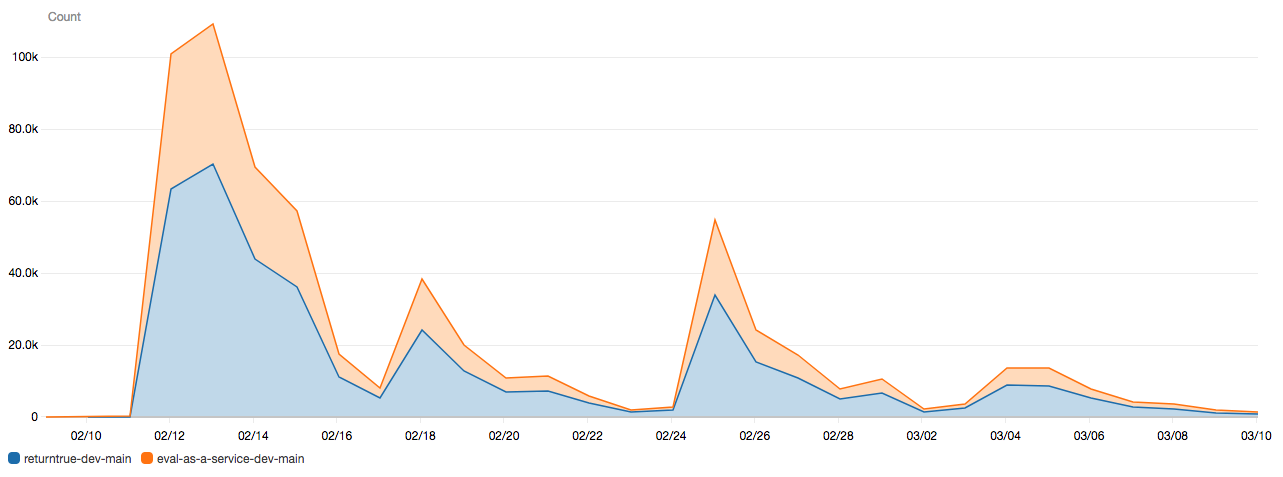
returntrue.win is a serverless application (original tweet)
The web application is one lambda. The code evaluation is done in another lambda. The database is very small and stored in DynamoDB.
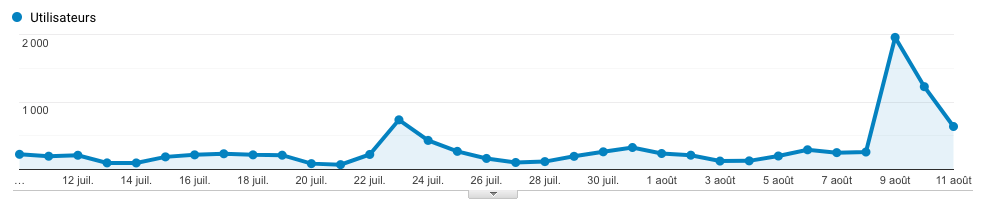
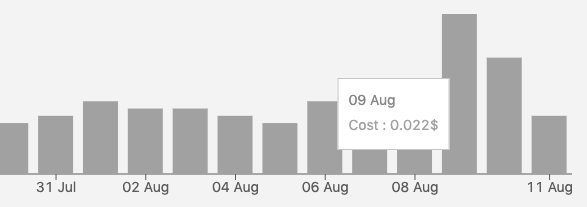
When the project was released it got 350k HTTP requests in 2 weeks, and 700k invocations across the 2 lambdas over 1 month. Not matter the trafic the performances were always the same. The total cost for that period was $3.
-
bref-symfony-demo is a Symfony application deployed as a lambda (original tweet)
-
serverless workers: I have been running workers in AWS lambda in a private project for several months now and I am very happy with the processing time (no queuing time since lambdas are run on demand), the costs ($0) and the maintenance (very low)
Please share your own experience in the comments.
TL/DR
Want to try out PHP as a serverless applications? Have a look at Bref.
To clear up vocabulary confusions:
- Serverless: a type of hosting where servers are managed for you and allocated dynamically
- FaaS (Function as a Service): serverless for code
- Lambda: a function
]]>